

The uncomfortable truth about deploying AI agents
Most teams don’t struggle to build AI agents. They struggle to deploy AI agents in environments where outcomes matter.
The industry narrative suggests the opposite:
- Better models → better outcomes
- More prompts → better performance
- More agents → more automation
This framing is incomplete.
AI doesn’t fail in production because models are weak. It fails because there is no system around the agents to carry decisions forward.
And that gap only shows up when you move from prototype to production.
The real problem founders face (but rarely name)
In early stages, everything looks like progress:
- Agents generate correct outputs
- Workflows can be mapped from experts
- Responses feel intelligent
- Demos succeed
This creates a false sense of readiness.
But these systems exist in controlled environments:
- Clean inputs
- Single-user flows
- No real consequences
- Manual oversight
The moment you attempt real-world AI agent deployment, the environment changes:
- Real client data replaces test inputs
- Multiple organizations use the same system
- Permissions and roles become critical
- Outputs trigger real actions
- Failures carry cost
At this stage, the problem is no longer intelligence.
It becomes system reliability.
Why most AI agent deployments break
There are a few flawed assumptions that repeatedly surface:
1. “If the agent works, the system works”
Agents can produce correct outputs without being operationally usable.
Correct ≠ deployable.
2. “We can structure later”
Workflow structure is often postponed in favor of speed.
But without orchestration:
- Decisions don’t chain
- Dependencies are unclear
- Execution becomes inconsistent
3. “Memory is optional”
Without memory:
- Agents restart every interaction
- Context is lost
- Continuous operation becomes impossible
4. “Logging is a later problem”
Without observability:
- You cannot trace failures
- You cannot audit decisions
- You cannot build trust
5. “Data will figure itself out”
Without proper pipelines:
- Inputs are inconsistent
- Outputs don’t integrate
- Systems fragment
These assumptions don’t break prototypes. They break production AI systems.
The shift: From agent capability to system reliability
At some point, every team building AI agents faces the same transition:
From:
- Can the agent respond correctly?
To:
- Can the system operate consistently?
This shift changes what matters:
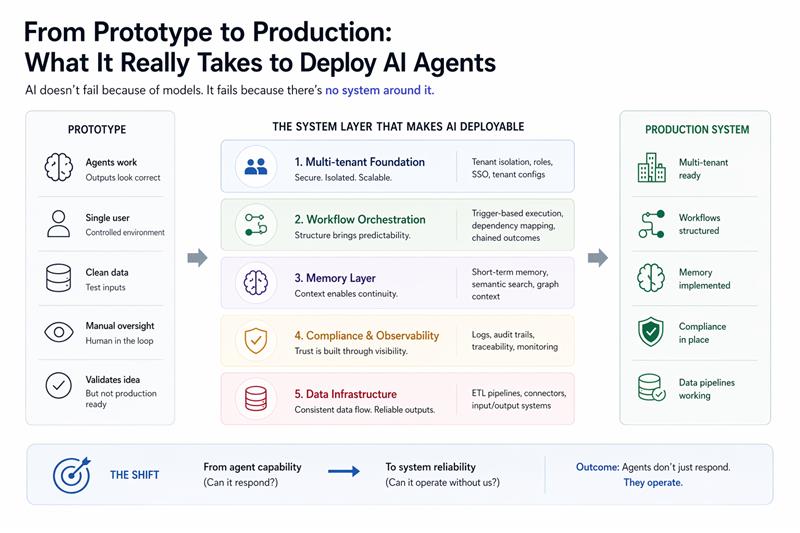
If this shift doesn’t happen early enough, deployments stall.
What’s actually missing in most AI systems
When we analyzed a real deployment scenario—moving autonomous surveillance agents from prototype to production in 8 weeks—the gaps were not in the AI.
They were structural.
1. Multi-tenant architecture
Without tenant separation:
- Data overlaps
- Permissions break
- Scaling becomes risky
What’s required:
- Tenant isolation
- Role-based access
- Tenant-specific configurations
2. AI workflow orchestration
Unstructured workflows lead to:
- Unpredictable execution
- Broken dependencies
- Inconsistent outcomes
What’s required:
- Trigger-based execution
- Clear dependency mapping
- Chained decision flows
3. Memory systems
Without memory:
- Agents cannot operate continuously
- Context is lost between steps
What’s required:
- Short-term interaction memory
- Semantic retrieval
- Structured knowledge layers
4. Compliance and observability
Without traceability:
- Systems cannot be trusted
- Failures cannot be diagnosed
What’s required:
- Detailed logs
- Audit trails
- Decision traceability
5. Data infrastructure
Without consistent data flow:
- Systems fragment
- Outputs don’t integrate
What’s required:
- ETL pipelines
- Data connectors
- Reliable input/output systems
A practical framework for deploying AI agents
Instead of thinking in terms of “building agents,” think in terms of system layers:

Most teams over-invest in Layer 1. Production systems depend on Layers 2–5.
What changes when you build the system layer
Once the system is structured:
- Agents stop behaving like tools
- They start behaving like operators
You begin to see:
- Consistent outputs across tenants
- Predictable workflow execution
- Continuous operation with memory
- Traceable decisions
- Reliable data flow
This is when AI moves from demonstration to deployment.
Execution reality: What it actually takes
In our case:
- Timeline: 8 weeks
- Environment: real client data
- Constraints: changing requirements, live feedback
- Goal: working system, not theoretical perfection
Key decisions:
- Prioritized system reliability over feature expansion
- Structured workflows before scaling agents
- Built observability early, not later
- Focused on failure handling, not just success paths
This is where most AI projects diverge.
Some continue optimizing models. Others start building systems.
Outcome: What a deployable AI system looks like
By the end of execution:
- Multi-tenant system operational
- Workflows structured and chained
- Memory layer implemented
- Compliance and logging in place
- Data pipelines stabilized
The agents didn’t change significantly.
The system around them did.
What founders should take away
If you’re building AI today, the critical question is not:
“How good is our model?”
It is:
“Can our system operate without us?”
If the answer is no, you don’t have deployment readiness. You have a prototype.
Where Lektik fits
This is the gap Lektik is built for.
Not building isolated AI capabilities. But designing systems where those capabilities can operate reliably.
Because in real environments:
AI is not a feature. It is a system.
Conclusion
The industry is not short on AI agents.
It is short on systems that can deploy them reliably.
Until that gap is addressed:
- Pilots will stall
- Trust will erode
- Deployments will fail quietly
The companies that win will not be those with better models.
They will be those who understand:
AI doesn’t fail because of intelligence. It fails because there’s no system around it.

