
Most AI demos succeed.
Most AI systems fail once they reach real operations.
The reason is rarely the model.
It is the system surrounding the model.
In controlled environments, AI performs well because the data is structured, curated, and predictable. Production environments are very different. Enterprise data is fragmented across platforms, documents, and operational systems.
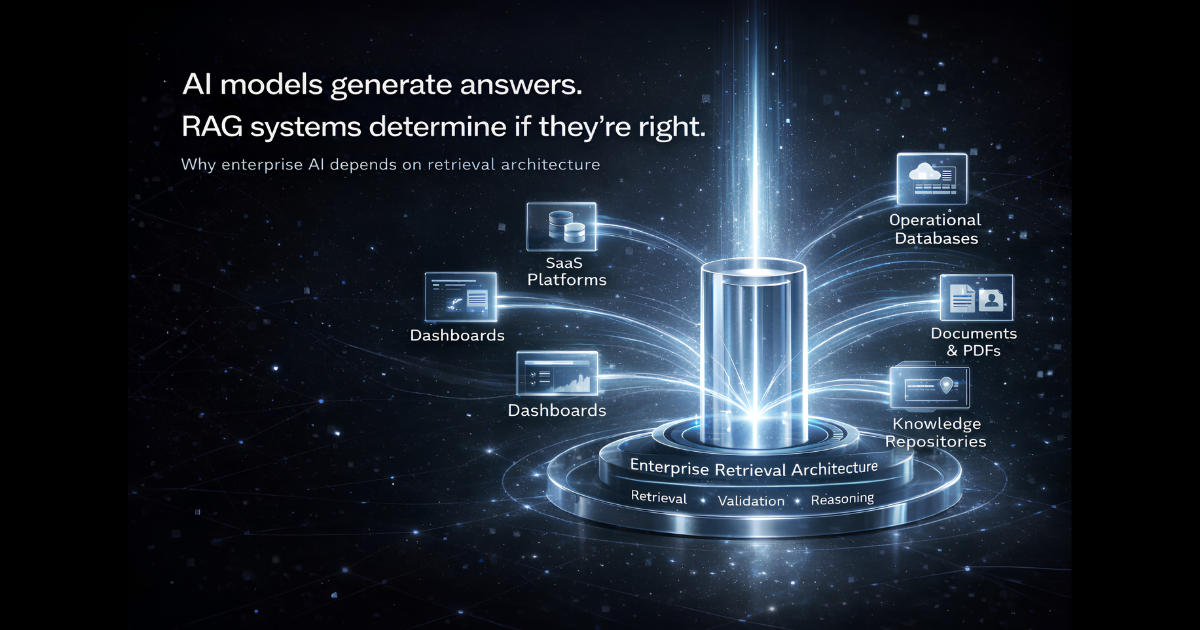
Organizations typically operate with information distributed across:
- SaaS platforms
- internal databases
- operational dashboards
- documents and knowledge repositories
- emails and internal communication channels
When AI systems encounter this reality, even advanced models struggle to produce consistent results.
This is why enterprise retrieval architectures — commonly implemented through Retrieval-Augmented Generation (RAG) — are becoming foundational for production AI systems.
The Core Problem: AI Meets Fragmented Enterprise Data
Many organizations begin their AI journey with a simple assumption:
If the model is powerful enough, the answers will be accurate.
In practice, the biggest challenge in enterprise AI is context retrieval, not model capability.
Operational knowledge rarely lives in one place. It is spread across multiple systems, each containing only a partial view of the business.
This creates a fundamental mismatch.
AI models are probabilistic systems.
Enterprise knowledge is fragmented, incomplete, and sometimes contradictory.
Without a system capable of retrieving and reconciling information across sources, AI systems quickly become:
- inconsistent in responses
- unreliable in edge cases
- difficult to maintain
- hard for organizations to trust
This is the problem modern enterprise retrieval systems are designed to solve.
A Practical Example: AI in Restaurant Operations Platforms
Consider a modern restaurant operations platform used by multi-location restaurant chains.
These platforms typically manage operational functions such as:
- inventory tracking
- procurement and supplier management
- workforce scheduling
- location-level sales analytics
- compliance and reporting
Each of these domains generates large volumes of operational data.
Now imagine a regional operations manager asking:
“Which restaurant locations are most likely to run into inventory shortages next week?”
At first glance, this appears to be a simple operational query.
In reality, answering it requires combining signals from several systems:
- current inventory levels
- historical sales velocity
- supplier delivery schedules
- upcoming promotions or demand spikes
- recent supply chain disruptions
The data exists within the organization.
But it is distributed across dashboards, databases, and operational tools.
Traditional analytics tools cannot easily combine these signals in real time.
This is where enterprise retrieval systems provide value.
Why Simple RAG Pipelines Break Down
Early implementations of Retrieval-Augmented Generation often followed a basic pattern:
Retrieve → Generate
A query retrieves documents, and the language model generates an answer.
This approach works well for simple knowledge retrieval.
However, it breaks down in complex operational environments where:
- queries may be ambiguous
- information may be incomplete
- data sources may conflict
- multiple systems must be consulted
For example:
“Why did food costs increase last week?”
Answering this may require correlating information from:
- supplier price updates
- procurement orders
- inventory waste reports
- menu promotions
- sales spikes across locations
A single retrieval step cannot reliably resolve these relationships.
This limitation has led to the evolution of multi-stage enterprise retrieval architectures.
The Architecture of Modern Enterprise Retrieval Systems
Production-grade AI systems increasingly rely on layered retrieval infrastructure rather than simple pipelines.
A typical architecture includes several stages.

Each stage solves a specific challenge in enterprise AI.
1. Query Understanding
The system interprets the user’s question and identifies the type of analysis required.
Example:
Inventory risk forecasting
2. Multi-Source Retrieval
Relevant information is retrieved across multiple systems:
- operational databases
- SaaS applications
- internal knowledge bases
- analytical dashboards
This stage often combines:
- vector search
- keyword search
- structured queries
- knowledge graph traversal
3. Context Validation
Enterprise data often contains inconsistencies.
The system identifies issues such as:
- delayed supplier shipments
- conflicting data sources
- incomplete inventory updates
Validation ensures the model works with trusted context.
4. Reasoning and Orchestration
An orchestration layer evaluates relationships across systems.
Example outcome:
Location A High sales velocity + delayed supplier delivery → High inventory risk Location B Low inventory + upcoming promotion → Moderate risk
5. Response Generation
The AI produces a structured operational insight:
Three restaurant locations are at elevated risk of inventory shortages next week due to supplier delays and increased demand.
The system includes the reasoning behind the conclusion, allowing operators to act with confidence.
What This Changes for Businesses
The real value of enterprise retrieval systems is not simply answering questions.
It is enabling AI to reconstruct operational reality from fragmented systems.
For restaurant operations platforms and similar enterprise environments, this enables organizations to:
- detect operational risks earlier
- improve supply chain visibility
- identify cost drivers faster
- support more informed decisions
Without reliable retrieval and validation mechanisms, AI cannot safely operate in complex operational environments.
Strategic Implications for AI Builders
The evolution of enterprise retrieval architecture is reshaping how AI products are designed.
The competitive moat moves to data systems
The long-term advantage of AI platforms will not come from the model alone but from the context architecture governing data retrieval.
Reliability becomes the differentiator
Organizations will adopt AI systems that consistently deliver trustworthy insights inside operational workflows.
AI becomes operational infrastructure
Instead of functioning as standalone tools, AI increasingly operates as a decision layer embedded within enterprise systems.
The Future of Enterprise AI
The industry remains heavily focused on models.
But the real challenge lies in systems.
Successful enterprise AI depends on the ability to:
- retrieve knowledge across fragmented systems
- structure operational context
- validate conflicting signals
- orchestrate intelligent decision processes
Modern retrieval architectures are rapidly becoming the foundation for AI systems that work reliably in production.
Everything else remains a demo.

